


Googles sökmotor är ett samspel av avancerade algoritmer, enorma databaser och kontinuerlig datainsamling från hela webben.
På sin mest grundläggande nivå är Google en sökmotor som hjälper användare att hitta relevant information bland miljarder webbsidor på internet. Men bakom den enkla gränssnittet döljer sig en komplex process som omfattar flera steg och avancerad teknologi.
Så låt oss ta en närmare titt på hur Google fungerar.
- Crawling (Genomgång):
- Google använder flera spindlar eller ”botar” som kontinuerligt genomsöker webben 24/7.
- Dessa spindlar börjar sin genomsökning genom att besöka en uppsättning kända webbsidor och följa länkar från dessa sidor till andra webbsidor.
- Spindlarna använder en hierarkisk strategi för att prioritera vilka sidor de ska besöka och hur ofta de ska besöka dem. Sidor som uppdateras oftare eller som har högre auktoritet får vanligtvis mer frekventa besök.
- URL Discovery (URL Upptäckt):
- Under genomsökningsprocessen upptäcker spindlarna nya URL:er genom att följa länkar från befintliga sidor, genom sitemaps som webbplatsägare tillhandahåller eller genom andra källor som RSS-flöden eller externa länkar.
- Fetch & Render (Hämta och Rendera):
- När spindlarna hittar en ny URL hämtar de dess innehåll, inklusive text, bilder, CSS och JavaScript-filer.
- Google kan även rendera sidan på samma sätt som en webbläsare för att se hur den ser ut för användare och för att extrahera dynamiskt genererat innehåll.
- Content Extraction (Innehållsextraktion):
- Efter att ha hämtat sidan extraherar Google relevanta texter och metadata från HTML-koden. Detta inkluderar rubriker, stycken, listor, titlar, meta-beskrivningar och annan strukturerad information.
- Indexering:
- Den extraherade informationen läggs till i Google’s index, som är en gigantisk databas med information om webbsidor över hela internet.
- Indexet organiserar informationen så att den kan återfinnas snabbt när användare gör sökningar.
- Canonicalization (Kanonisering):
- Google använder kanonisering för att hantera duplicerat innehåll och bestämma den mest auktoritativa versionen av en sida.
- Detta innebär att om det finns flera versioner av samma innehåll (t.ex. www och non-www versioner, HTTP och HTTPS versioner), väljer Google vanligtvis en primär version att indexera och visa i sökresultatet.
Canonicalization löser detta problem genom att använda en tagg i HTML-koden, kallad ”rel=canonical”, för att ange den kanoniska versionen av en sida. Genom att inkludera denna tagg på de olika versionerna av en sida kan webbplatsägaren tydligt ange vilken version som är den primära och föredragna versionen för sökmotorer att indexera och ranka. När en sökmotor stöter på en rel=canonical-tagg på en sida kommer den att förstå att den kanoniska versionen av den sidan är den som anges i taggen. Detta hjälper till att konsolidera rankingen och trafiken till den kanoniska versionen och undviker problem med duplicerat innehåll. Canonicalization är särskilt viktigt för e-handelswebbplatser med produktsidor som kan genereras dynamiskt med olika sorterings- och filtreringsparametrar i URL:en. Genom att använda rel=canonical-taggar kan webbplatsägare undvika att duplicera innehåll och maximera effektiviteten i sin SEO-strategi.
- Crawl Budget :
- Google fördelar resurser för genomsökning av webbplatser baserat på dess ”Crawl Budget”, vilket är det maximala antalet sidor och hur ofta de genomsöks.
Faktorer som påverkar crawl budget inkluderar:
- Sidans popularitet och relevans: Sidor som anses vara mer relevanta och populära tenderar att tilldelas ett större crawl budget.
- Sidans struktur och länkkvalitet: En väldesignad webbplats med en tydlig hierarki och internlänkar kan få ett större crawl budget än en rörig webbplats.
- Svaretid och prestanda: Snabbt laddande sidor som svarar snabbt på förfrågningar tenderar att få en högre andel av crawl budgeten.
- Robots.txt och nofollow-länkar: Direktiv i robots.txt-filen och användningen av nofollow-länkar kan påverka hur sökmotorer allokerar sin crawl budget till olika delar av en webbplats.
- Ändringsfrekvens: Om en webbplats ofta uppdateras kan sökmotorer besöka den oftare för att hålla sitt index uppdaterat.
För webbplatsägare och webbutvecklare är det viktigt att förstå crawl budget och optimera sin webbplats för att säkerställa att sökmotorer spenderar sin crawl budget på de viktigaste och mest relevanta delarna av webbplatsen. Detta kan hjälpa till att förbättra synligheten och rankingen i sökresultaten.
- Google fördelar resurser för genomsökning av webbplatser baserat på dess ”Crawl Budget”, vilket är det maximala antalet sidor och hur ofta de genomsöks.
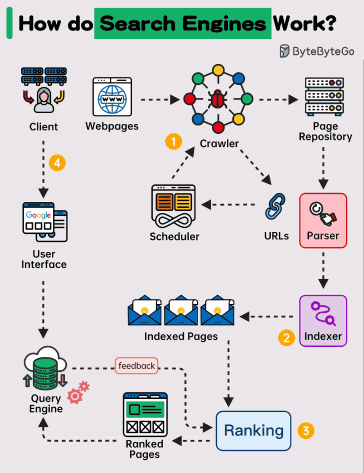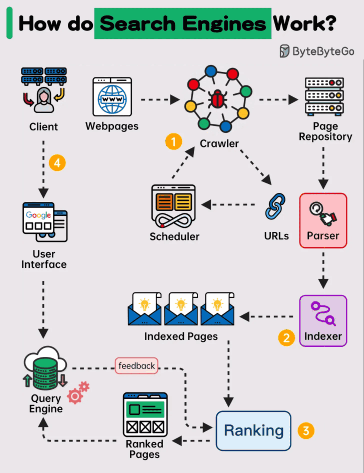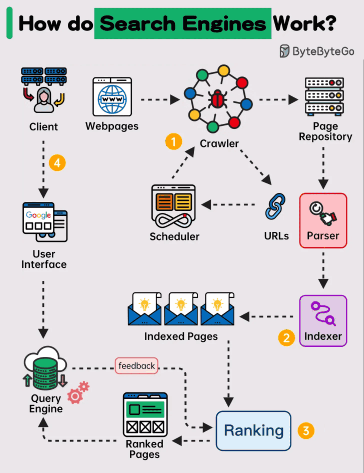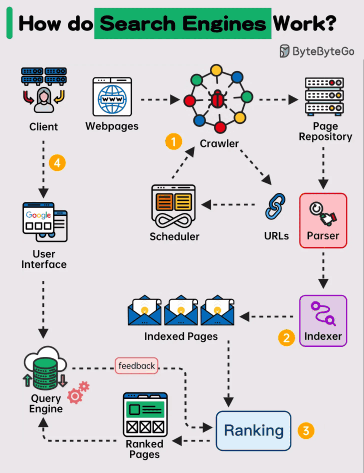
Genom denna process indexerar Google miljontals sidor varje dag och strävar efter att göra relevant och aktuellt innehåll tillgängligt för användare runt om i världen när de söker på internet.